Cominciamo col capire cosa sono le catene di Markov. Prendiamo un meteo, in cui si hanno soltanto due stati:
- sole,
 ;
;
- nuvoloso,
 .
.
Se oggi c'è il sole, allora domani ci sarà
- sole con probabilità
 ;
;
- nuvoloso con probabilità
 .
.
Al contrario, se oggi è nuvoloso, allora domani ci sarà
- sole con probabilità
 ;
;
- nuvoloso con probabilità .

Questa è una catena di Markov. Il tempo di domani dipende dal tempo di oggi, e non dal tempo di ieri; inoltre, la probabilità che esce da ogni stato è unitaria, quindi anche la probabilità che in un dato istante si sia in un determinato punto soddisferà anch'essa la proprietà di uniterietà.
Definizione: Processo di Markov
Il processo

è un processo di Markov se

In altre parole, possiamo scrivere che una variabile casuale  dipende solo dalla variabile casuale
dipende solo dalla variabile casuale  , mentre è indipendente da tutte le variabili casuali precedenti l'istante
, mentre è indipendente da tutte le variabili casuali precedenti l'istante  .
.
Implicazioni:
- la probabilità del futuro, dato passato e presente, dipende solo dal presente.
- la probabilità del futuro, congiunta a quella del passato e conoscendo il presente, è

- Gli eventi che soddisfano questa seconda condizione sono detti condizionalmente indipendenti, cioè sono indipendenti soltanto se vi è la conoscenza dello stato intermedio. Nel caso in cui non si conosca il presente, allora passato e futuro non sono più indipendenti.
Densità di probabilità del processo di Markov
[modifica]
![{\displaystyle \left\{{\begin{aligned}&f_{X(t_{n})X(t_{n-1})\cdots X(t_{1})}(x_{n},x_{n-1},\cdots ,x_{1})=\\&=f_{X(t_{n})|X(t_{n-1}),X(t_{n-2})\cdots X(t_{1})}(x_{n}|x_{n-1},x_{n-2}\cdots x_{1})\times \cdots \times f_{X(t_{2})|X(t_{1})}(x_{2}|x_{1})\times f_{X(t_{1})}(x_{1})\\&=f_{X(t_{n})|X(t_{n-1})}(x_{n}|x_{n-1})\times \cdots \times f_{X(t_{2})|X(t_{1})}(x_{2}|x_{1})\times f_{X(t_{1})}(x_{1})\\&=\left[\Pi _{k=1}^{n-1}f_{X(t_{k+1})|X(t_{k})}(x_{k+1}|x_{k})\right]\cdot f_{X(t_{1})}(x_{1})\end{aligned}}\right.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/370034f83654f58395d2f82bc05f68bfbe127349)
Per caratterizzare una catena di Markov è sufficiente conoscere la densità di probabilità del second'ordine, non serve scendere fino all' -esimo ordine. In questo modo, la trattazione diventa molto più semplice, fino a renderla quasi banale.
-esimo ordine. In questo modo, la trattazione diventa molto più semplice, fino a renderla quasi banale.
I processi di Markov si possono classificare in base allo stato/tempo continuo/discreto:
- stato continuo e tempo continuo: processo a tempo continuo;
- stato continuo e tempo discreto: processo a tempo discreto;
- stato discreto e tempo continuo: catena a tempo continuo;
- stato discreto e tempo discreto: catena a tempo discreto.
Catene di Markov a tempo discreto
[modifica]Si ha


che sono due insiemi discreti. La catena di Markov è caratterizzata da due quantità:
- la probabilità incondizionata

- la matrice delle probabilità di transizione
 .
.
Si ha
![{\displaystyle P_{i}(n)\in [0,1]\ \forall i\in S,\forall n\in T\ |\ \sum _{i\in S}P_{i}(n)=1}](https://wikimedia.org/api/rest_v1/media/math/render/svg/afb027dc837c0d18b39089a18cb5cc3ef7d3ede8)
cioè, per ogni istante, la somma delle probabilità di tutti gli stati è unitaria; noto l'alfabeto  , la probabilità incondizionata si può scrivere come
, la probabilità incondizionata si può scrivere come
![{\displaystyle {\underline {P}}(n)=[P_{1}(n)\ P_{2}(n)\ \cdots \ P_{|s|}(n)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f16c1d8be366d87a4c4b54f198d4bebdfce7d727)
La stessa condizione si può esprimere con
![{\displaystyle {\underline {P}}\cdot e^{T}=1\ e=[1\ 1\ \cdots \ 1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/53d5d8b5fe8e13b28427ed6abb7c312b4e25f16c)
Fissati due istanti temporali  e dato lo stato di partenza , la somma delle probabilità degli stati di arrivo è unitaria.
e dato lo stato di partenza , la somma delle probabilità degli stati di arrivo è unitaria.
![{\displaystyle {\underline {P}}(m,n)=\left[{\begin{matrix}P_{1,1}(m,n)&P_{1,2}(m,n)&\cdots &P_{1,|s|}(m,n)\\P_{2,1}(m,n)&P(2,2)(m,n)&\cdots &P_{2,|s|}(m,n)\\\vdots &\vdots &\ddots &\vdots \\P_{|s|,1}(m,n)&P_{|s|,2}(m,n)&\cdots &P_{|s|,|s|}(m,n)\end{matrix}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2759a69ef7936c7735a97d844583175ee766e05b)
dove la somma dei valori di ogni singola riga è 
![{\displaystyle \sum _{i=1,2,\cdots |s|}P_{i,j}(m,n)=1\ \forall j\in [0,1,\cdots |s|]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6b8c290f357ceae3ee0ee23c94d2580d41bf121a)
![{\displaystyle {\underline {P}}(m,n)\cdot e^{T}=e^{T}=[1\ 1\ \cdots \ 1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0ed1e9fe862d9361d66dc0ff98d9468a9ba90d29)
Per ogni coppia  , il valore di
, il valore di  sarà diverso. Si ha
sarà diverso. Si ha



Quest'ultima è detta l'equazione di Chapman e Kolmogorov, che in forma matriciale si può scrivere come

da cui si ha

Per caratterizzare una catena di Markov, basta conoscere:



Esempio: Caso 1
Esempio: Caso 2
Definizione: Catena di Markov omogenea
Una catena di Markov è detta omogenea se

ossia, la matrice di probabilità di transizione ad un passo

è la stessa per tutti i

.
Esempio:
Definizione: Distribuzione stazionaria
In generale, una catena di Markov può avere più distribuzioni stazionarie.
Esempio:
Definizione: Catena di Markov irriducibile
Una catena di Markov si dice irriducibile se non è possibile portare la matrice di probabilità di transizione in una forma diagonale a blocchi, del tipo
![{\displaystyle \left[{\begin{matrix}\left\{{\begin{matrix}0&1\\1&0\end{matrix}}\right\}&{\begin{matrix}0\\0\end{matrix}}\\{\begin{matrix}0&0\end{matrix}}&1\end{matrix}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f9a2135a4ae5bb6940013da9037dad88f87fcd9e)
Se una catena di Markov è irriducibile, allora la distribuzione stazionaria esiste ed è unica.
Definizione: Distribuzione limite
Una distribuzione stazionaria

si dice distribuzione limite se

Questo deve valere

, cioè per qualsiasi condizione iniziale.
Definizione: Catena di Markov aperiodica
Una catena di Markov omogenea ed irriducibile è aperiodica se il massimo comun divisore delle lunghezze di tutti i cammini chiusi che si possono individuare sul diagramma delle transizioni è pari a
.
Esempio:
Catena periodica di periodo

:

In questo caso,

.
Esempio:
Catena di Markov aperiodica:
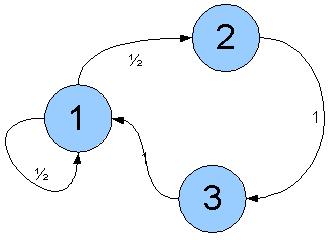
In questo caso,

.
Se una catena di Markov omogenea ed irriducibile è aperiodica, allora la distribuzione stazionaria è anche distribuzione limite. Per queste catene di Markov, a regime la probabilità assoluta è indipendente dal tempo, dando origine a processi stazionari.
Nota: una distribuzione è una distribuzione limite se
![{\displaystyle \lim _{n\to \infty }{\underline {\underline {P}}}^{n}=\left[{\begin{matrix}{\underline {\Pi }}\\{\underline {\Pi }}\\{\underline {\Pi }}\end{matrix}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/792005af0398712866bb3726d376a3f95a93a4a9)
Definizione: Matrice doppiamente stocastica
Una matrice di probabilità di transizione è doppiamente stocastica se la somma degli elementi di ciascuna colonna è unitario; in tal caso, la distribuzione limite risulta essere
![{\displaystyle {\underline {\Pi }}=\left[{\frac {1}{|s|}}\ {\frac {1}{|s|}}\ \cdots \ {\frac {1}{|s|}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c9e4fa48c9b27bd0e607da257be5ce91e96acf1b)
Esempio:


Si ha
![{\displaystyle {\underline {\underline {P}}}=\left[{\begin{matrix}{\frac {1}{4}}&{\frac {1}{4}}&{\frac {1}{2}}\\{\frac {1}{4}}&{\frac {1}{4}}&{\frac {1}{2}}\\{\frac {1}{2}}&{\frac {1}{2}}&0\end{matrix}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/eefb8d37b4cecd3f37a62516aad19974932553c8)
![{\displaystyle {\underline {\Pi }}=[{\underline {\pi _{1}}}\ {\underline {\pi _{2}}}\ \cdots \ {\underline {\pi _{3}}}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b539e3592a095d7e04002bb1a179c9337448d70b)
da cui


si ottiene
![{\displaystyle {\underline {\Pi }}=\left[{\frac {1}{3}}\ {\frac {1}{3}}\ {\frac {1}{3}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a55b53fe64072295fd9dc646d0e9c3d1b89ff6f2)
che è una matrice stocastica.




![{\displaystyle {\underline {P}}(1)={\underline {P}}(0)\cdot {\underline {\underline {P}}}=[1\ 0]\cdot \left[{\begin{matrix}0&1\\1&0\end{matrix}}\right]=[0\ 1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e12a0d725c1fa4c2899c183bc7df84f18260f8e1)
![{\displaystyle {\underline {P}}(2)={\underline {P}}(0)\cdot {\underline {\underline {P}}}^{2}=[1\ 0]\cdot \left[{\begin{matrix}0&1\\1&0\end{matrix}}\right]\cdot \left[{\begin{matrix}0&1\\1&0\end{matrix}}\right]=[1\ 0]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4d1d622190f1ffdd67563b87e75e90b3ce858d42)
![{\displaystyle P(2m)=[1\ 0]\ \forall m\in \mathbb {N} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/fac137b2774e1aca942fdc4d1ebb40010155056f)
![{\displaystyle P(2m+1)=[0\ 1]\ \forall m\in \mathbb {N} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/f511973dcb36bd1578c1ae2aa34a21e6b6cc517a)
![{\displaystyle {\underline {\underline {P}}}=\left[{\begin{matrix}0&1\\1&0\end{matrix}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/073ca5e8a7dc23280c82be44ffc91b13a543aaf4)
![{\displaystyle P(0)=\left[{\frac {1}{2}}\ {\frac {1}{2}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d883a55ad37c7592f04f2a3461b0548912359235)
![{\displaystyle {\underline {P}}(1)={\underline {P}}(0)\cdot {\underline {\underline {P}}}=\left[{\frac {1}{2}}\ {\frac {1}{2}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8195e296ebe719dc15b7aa3108460f3efea04a57)
![{\displaystyle {\underline {P}}(2)={\underline {P}}(0)\cdot {\underline {\underline {P}}}^{2}=\left[{\frac {1}{2}}\ {\frac {1}{2}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bae832521592d2b223964aff822616cbcedb9f66)
![{\displaystyle {\underline {P}}(m)=\left[{\frac {1}{2}}\ {\frac {1}{2}}\right]\ \forall m\in T}](https://wikimedia.org/api/rest_v1/media/math/render/svg/81631b7be951745f06d1c8fd83a109ae58d0bb0d)

![{\displaystyle {\underline {\underline {P}}}=\left[{\begin{matrix}P_{11}&P_{12}\\P_{21}&P_{22}\end{matrix}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3e1275a76e4f9075a907cc0e5b4004c0c7600be9)
![{\displaystyle {\underline {P}}(0)=[P_{1}\ P_{2}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a77eee63b90e0ebdb7e409ea99d9415df1529444)

![{\displaystyle {\underline {\Pi }}=[\pi _{1}\ \pi _{2}\ \cdots \ \pi _{|s|}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0ef9531cd2465636c2186bbac4799fc28c2a3404)




![{\displaystyle {\underline {\underline {P}}}=\left[{\begin{matrix}0&1&0\\1&0&0\\0&0&1\end{matrix}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cf12462ed3e090e835e82e3d2113772d87a85bd5)
![{\displaystyle \Pi _{1}=\left[{\frac {1}{2}}\ {\frac {1}{2}}\ 0\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fcca1a7403d9cdea62312781ff08c9ff9db2c5b6)
![{\displaystyle \Pi _{2}=[0\ 0\ 1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3b4b95f5608337fbffea733e777cf15c11413642)
![{\displaystyle \Pi _{3}=\left[{\frac {1}{4}}\ {\frac {1}{4}}\ {\frac {1}{4}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/047389069bd5ef6d0bf82a0ec5df2e79b0d349df)



